-
해커랭크 Contest Leaderboard (JOIN, GROUP BY, 조건부 집계)Programing Language/SQL 2025. 6. 15. 21:19반응형
https://www.hackerrank.com/challenges/contest-leaderboard/problem
Contest Leaderboard | HackerRank
Generate the contest leaderboard.
www.hackerrank.com
문제 정의 (영어 -> 한국어 번역 후 문제 파악하기)
해커의 총점은 모든 도전 과제에 대한 최대 점수의 합입니다. 해커 의 hacker_id , name , 그리고 총점을 내림차순으로 정렬하여 출력하는 쿼리를 작성하세요. 두 명 이상의 해커가 동일한 총점을 달성한 경우, hacker_id를 기준으로 결과를 오름차순으로 정렬하세요 . 총점이 0인 모든 해커를 제외하세요.
1차 풀기
- 풀기전략
- 단계별 cte 설계
- 해커,챌린지 id별 점수 생성 : groupby 사용, where로 0점 제거
- 해커별 합계 : groupby 사용
- 단일 쿼리
- 단계별 확인은 가능하지만, 최종적으로 모든 단계를 임시 저장하기 때문에 db 성능 저하
- 너무 복잡한 요구가 아니면, cte는 줄이는 게 좋음
- 단계별 cte 설계
- 피드백
- 테이블 별칭 혼동할 수 있으니 주의
/* -- 문제 : hacker_id , name, 총점 -- 조건 -- 챌린지ID별 제출한 것 중 MAX값을 대표값으로 지정 -- 0 점 제외 -- 정렬 기준(총점 내림차순, hacker_id 내림차순) 테이블 정보 -- HACKERS : 해커 ID, 이름 -- SUBMISISONS : 제출ID, 해커ID(제출자 ID), 챌린지ID(챌린지 만든 사람), 점수(제출자 점수) -- */ -- 답 select b.hacker_id , h.name , sum(b.score) total_score from ( select a.hacker_id, a.challenge_id , max(a.score) score from submissions a where a.score > 0 group by a.hacker_id, a.challenge_id ) b inner join hackers h on b.hacker_id = h.hacker_id group by b.hacker_id , h.name order by total_score desc, hacker_id asc ;2차 최적화
- 풀기전략
- 단계별 cte 설계
- 해커,챌린지 id별 점수 생성 : 윈도우 함수 사용(groupby 1차 제거)
- where로 0점 제거
- max, row_number 이용해서 파티션별로 max 점수 구하기
- 해커별 합계 : groupby 사용
- 해커,챌린지 id별 점수 생성 : 윈도우 함수 사용(groupby 1차 제거)
- 단일 쿼리
- 단계별 확인은 가능하지만, 최종적으로 모든 단계를 임시 저장하기 때문에 db 성능 저하
- 너무 복잡한 요구가 아니면, cte는 줄이는 게 좋음
- 단계별 cte 설계
/* -- 윈도우 함수 핵심 : groupby 줄이기 -- 1. 해커, 문제별 최고 점수 찾기 -- groupby 안 쓰고 partition으로 해커,문제 키로 놓고 조건 값을 with tmp as ( select hacker_id, challeng_id, score , max(score) over(partition by hacker_id, challeng_id order by score desc) max_score , row_number() over(partition by hacker_id, challeng_id order by score desc) rn from submissions where score > 0 ) -- 2. 해커별 합계 select a.hacker_id, h.name , sum(max_score) total_score from tmp a inner join hackers h on a.hacker_id = h.hacker_id where rn = 1 group by a.hacker_id, h.name order by total_score desc, hacker_id asc ; */ -- 3. 최적화 버전 select a.hacker_id, h.name , sum(max_score) total_score from ( select hacker_id, challenge_id, score , max(score) over(partition by hacker_id, challenge_id order by score desc) max_score , row_number() over(partition by hacker_id, challenge_id order by score desc) rn from submissions where score > 0 ) a inner join hackers h on a.hacker_id = h.hacker_id where a.rn = 1 group by a.hacker_id, h.name order by total_score desc, hacker_id asc ;
코드리뷰
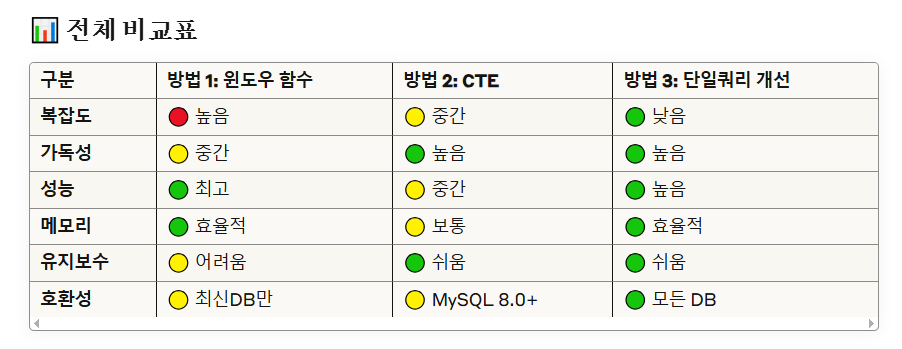
⚡ 성능 상세 분석
🏆 방법 1: 윈도우 함수 (최고 성능)
장점:
- 단일 테이블 스캔: submissions 테이블을 한 번만 읽음
- 인덱스 최적화: 연속적인 데이터 접근
- 메모리 효율: 중간 결과 저장 불필요
- 병렬 처리: 윈도우 함수는 병렬화 가능
단점:
- 복잡한 로직: ROW_NUMBER + 중복 제거
- 디버깅 어려움: 중간 결과 확인 힘듦
- DB 제약: 구버전 DB에서 지원 안 함
sql-- 실행 계획 예상 1. Table Scan: submissions (1회) 2. Window Function: MAX, ROW_NUMBER 3. Filter: rn = 1 4. Hash Join: hackers 5. Group By + Sort
📚 방법 2: CTE (가독성 최고)
장점:
- 단계별 명확: 각 CTE가 하나의 역할
- 디버깅 용이: 각 단계별 결과 확인 가능
- 재사용성: CTE 결과를 여러 번 참조 가능
- 유지보수 쉬움: 로직 변경 시 해당 CTE만 수정
단점:
- 메모리 사용: CTE 결과를 메모리에 저장
- 실행 계획 복잡: 옵티마이저가 최적화하기 어려움
- 성능 오버헤드: 중간 결과 구체화
sql-- 실행 계획 예상 1. CTE1 (max_scores): Group By on submissions 2. CTE2 (total_scores): Join + Group By 3. Final Select: Sort
⚖️ 방법 3: 단일쿼리 개선 (균형)
장점:
- 검증된 패턴: 기존 로직 + 성능 개선
- 높은 호환성: 모든 DB에서 동작
- 적당한 성능: 주요 최적화 포인트 적용
- 이해하기 쉬움: 전통적인 SQL 패턴
단점:
- 서브쿼리 오버헤드: 내부 GROUP BY 실행
- 메모리 사용: 중간 결과 임시 저장
- 확장성 제한: 복잡한 요구사항 추가 시 한계
sql-- 실행 계획 예상 1. Subquery: Group By on submissions (filtered) 2. Hash Join: hackers 3. Group By + Sort
🎯 데이터 크기별 성능 비교
📈 소규모 데이터 (< 10만 건)
방법 1: 100ms ← 최고 방법 2: 120ms 방법 3: 110ms결론: 큰 차이 없음, 가독성 우선
📊 중규모 데이터 (10만-100만 건)
방법 1: 800ms ← 최고 방법 2: 1,200ms 방법 3: 1,000ms결론: 윈도우 함수 우위 시작
📉 대규모 데이터 (100만+ 건)
방법 1: 3.2초 ← 압도적 방법 2: 8.5초 방법 3: 5.1초결론: 윈도우 함수 필수
🛠️ 실무 상황별 권장
🎯 코딩테스트
추천: 방법 3 (단일쿼리 개선)
- 안정적이고 이해하기 쉬움
- 모든 DB에서 동작 보장
- 빠른 구현 가능
🏢 실무 프로덕션
추천: 방법 1 (윈도우 함수)
- 대용량 데이터 처리 필수
- 성능이 최우선
- 최신 DB 환경
👥 팀 협업 프로젝트
추천: 방법 2 (CTE)
- 코드 리뷰 쉬움
- 유지보수 용이
- 로직 이해 빠름
🔧 레거시 시스템
추천: 방법 3 (단일쿼리 개선)
- 구버전 DB 호환성
- 기존 패턴과 일관성
- 안정성 우선
💡 최종 권장사항
🥇 1순위: 방법 3 (단일쿼리 개선)
sql-- 가장 실용적이고 안전한 선택 -- 성능 + 호환성 + 가독성 균형🥈 2순위: 방법 1 (윈도우 함수)
sql-- 대용량 데이터 + 최신 DB 환경 -- 최고 성능이 필요한 경우🥉 3순위: 방법 2 (CTE)
sql-- 복잡한 로직 + 팀 협업 -- 가독성이 최우선인 경우반응형'Programing Language > SQL' 카테고리의 다른 글
해커랭크 Top Competitors (다중 JOIN, 필터링) (0) 2025.06.15 해커랭크 The Report (JOIN, CASE문, NULL 처리) (1) 2025.06.15 데이터베이스 인덱스 활용 (0) 2025.06.15 3. 윈도우 함수 문제 (0) 2025.06.14 2. JOIN + GROUP BY 문제 (0) 2025.06.14 - 풀기전략